
同步操作
同步操作
"同步操作"是指在计算机科学和信息技术中的一种操作方式,其中不同的任务或操作按顺序执行,一个操作完成后才能开始下一个操作。在多线程编程中,各个任务通常需要通过同步设施进行相互协调和等待,以确保数据的一致性和正确性。
本章的主要内容有:
条件变量
std::future等待异步任务在规定时间内等待
Qt 实现异步任务的示例
其它 C++20 同步设施:信号量、闩与屏障
本章将讨论如何使用条件变量等待事件,介绍 future 等标准库设施用作同步操作,使用Qt+CMake 构建一个项目展示多线程的必要性,介绍 C++20 引入的新的同步设施。
等待事件或条件
假设你正在一辆夜间运行的地铁上,那么你要如何在正确的站点下车呢?
一直不休息,每一站都能知道,这样就不会错过你要下车的站点,但是这会很疲惫。
可以看一下时间,估算一下地铁到达目的地的时间,然后设置一个稍早的闹钟,就休息。这个方法听起来还行,但是你可能被过早的叫醒,甚至估算错误导致坐过站,又或者闹钟没电了睡过站。
事实上最简单的方式是,到站的时候有人或者其它东西能将你叫醒(比如手机的地图,到达设置的位置就提醒)。
这和线程有什么关系呢?其实第一种方法就是在说”忙等待(busy waiting)”也称“自旋“。
bool flag = false;
std::mutex m;
void wait_for_flag(){
std::unique_lock<std::mutex> lk{ m };
while (!flag){
lk.unlock(); // 1 解锁互斥量
lk.lock(); // 2 上锁互斥量
}
}第二种方法就是加个延时,这种实现进步了很多,减少浪费的执行时间,但很难确定正确的休眠时间。这会影响到程序的行为,在需要快速响应的程序中就意味着丢帧或错过了一个时间片。循环中,休眠②前函数对互斥量解锁①,再休眠结束后再对互斥量上锁,让另外的线程有机会获取锁并设置标识(因为修改函数和等待函数共用一个互斥量)。
void wait_for_flag(){
std::unique_lock<std::mutex> lk{ m };
while (!flag){
lk.unlock(); // 1 解锁互斥量
std::this_thread::sleep_for(std::chrono::milliseconds(100)); // 2 休眠
lk.lock(); // 3 上锁互斥量
}
}第三种方式(也是最好的)实际上就是使用条件变量了。通过另一线程触发等待事件的机制是最基本的唤醒方式,这种机制就称为“条件变量”。
C++ 标准库对条件变量有两套实现:std::condition_variable 和 std::condition_variable_any,这两个实现都包含在 <condition_variable> 头文件中。
condition_variable_any 类是 std::condition_variable 的泛化。相对于只在 std::unique_lock<std::mutex> 上工作的 std::condition_variable,condition_variable_any 能在任何满足可基本锁定(BasicLockable)要求的锁上工作,所以增加了 _any 后缀。显而易见,这种区分必然是 any 版更加通用但是却有更多的性能开销。所以通常首选 std::condition_variable。有特殊需求,才会考虑 std::condition_variable_any。
std::mutex mtx;
std::condition_variable cv;
bool arrived = false;
void wait_for_arrival() {
std::unique_lock<std::mutex> lck(mtx);
cv.wait(lck, []{ return arrived; }); // 等待 arrived 变为 true
std::cout << "到达目的地,可以下车了!" << std::endl;
}
void simulate_arrival() {
std::this_thread::sleep_for(std::chrono::seconds(5)); // 模拟地铁到站,假设5秒后到达目的地
{
std::lock_guard<std::mutex> lck(mtx);
arrived = true; // 设置条件变量为 true,表示到达目的地
}
cv.notify_one(); // 通知等待的线程
}std::mutex mtx: 创建了一个互斥量,用于保护共享数据的访问,确保在多线程环境下的数据同步。std::condition_variable cv: 创建了一个条件变量,用于线程间的同步,当条件不满足时,线程可以等待,直到条件满足时被唤醒。bool arrived = false: 设置了一个标志位,表示是否到达目的地。
在 wait_for_arrival 函数中:
std::unique_lock<std::mutex> lck(mtx): 使用互斥量创建了一个独占锁。cv.wait(lck, []{ return arrived; }): 阻塞当前线程,释放(unlock)锁,直到条件被满足。一旦条件满足,即
arrived变为 true,并且条件变量cv被唤醒(包括虚假唤醒),那么当前线程会重新获取锁(lock),并执行后续的操作。
在 simulate_arrival 函数中:
std::this_thread::sleep_for(std::chrono::seconds(5)): 模拟地铁到站,暂停当前线程 5 秒。设置
arrived为 true,表示到达目的地。cv.notify_one(): 唤醒一个等待条件变量的线程。
这样,当 simulate_arrival 函数执行后,arrived 被设置为 true,并且通过 cv.notify_one() 唤醒了等待在条件变量上的线程,从而使得 wait_for_arrival 函数中的等待结束,可以执行后续的操作,即输出提示信息。
条件变量的 wait 成员函数有两个版本,以上代码使用的就是第二个版本,传入了一个谓词。
void wait(std::unique_lock<std::mutex>& lock); // 1
template<class Predicate>
void wait(std::unique_lock<std::mutex>& lock, Predicate pred); // 2②等价于:
while (!pred())
wait(lock);第二个版本只是对第一个版本的包装,等待并判断谓词,会调用第一个版本的重载。这可以避免“虚假唤醒(spurious wakeup)”。
条件变量虚假唤醒是指在使用条件变量进行线程同步时,有时候线程可能会在没有收到通知的情况下被唤醒。问题取决于程序和系统的具体实现。解决方法很简单,在循环中等待并判断条件可一并解决。使用 C++ 标准库则没有这个烦恼了。
我们也可以简单看一下 MSVC STL 的源码实现:
void wait(unique_lock<mutex>& _Lck) noexcept {
_Cnd_wait(_Mycnd(), _Lck.mutex()->_Mymtx());
}
template <class _Predicate>
void wait(unique_lock<mutex>& _Lck, _Predicate _Pred) {
while (!_Pred()) {
wait(_Lck);
}
}线程安全的队列
在本节中,我们介将绍一个更为复杂的示例,以巩固我们对条件变量的学习。为了实现一个线程安全的队列,我们需要考虑以下两个关键点:
当执行
push操作时,需要确保没有其他线程正在执行push或pop操作;同样,在执行pop操作时,也需要确保没有其他线程正在执行push或pop操作。当队列为空时,不应该执行
pop操作。因此,我们需要使用条件变量来传递一个谓词,以确保在执行pop操作时队列不为空。
基于以上思考,我们设计了一个名为 threadsafe_queue 的模板类,如下:
template<typename T>
class threadsafe_queue {
mutable std::mutex m; // 互斥量,用于保护队列操作的独占访问
std::condition_variable data_cond; // 条件变量,用于在队列为空时等待
std::queue<T> data_queue; // 实际存储数据的队列
public:
threadsafe_queue() {}
void push(T new_value) {
{
std::lock_guard<std::mutex> lk { m };
data_queue.push(new_value);
}
data_cond.notify_one();
}
// 从队列中弹出元素(阻塞直到队列不为空)
void pop(T& value) {
std::unique_lock<std::mutex> lk{ m };
data_cond.wait(lk, [this] {return !data_queue.empty(); });
value = data_queue.front();
data_queue.pop();
}
// 从队列中弹出元素(阻塞直到队列不为空),并返回一个指向弹出元素的 shared_ptr
std::shared_ptr<T> pop() {
std::unique_lock<std::mutex> lk{ m };
data_cond.wait(lk, [this] {return !data_queue.empty(); });
std::shared_ptr<T> res { std::make_shared<T>(data_queue.front()) };
data_queue.pop();
return res;
}
bool empty()const {
std::lock_guard<std::mutex> lk (m);
return data_queue.empty();
}
};请无视我们省略的构造、赋值、交换、try_xx 等操作。以上示例已经足够。
光写好了肯定不够,我们还得测试运行,我们可以写一个经典的:”生产者消费者模型“,也就是一个线程 push ”生产“,一个线程 pop ”消费“。
void producer(threadsafe_queue<int>& q) {
for (int i = 0; i < 5; ++i) {
q.push(i);
}
}
void consumer(threadsafe_queue<int>& q) {
for (int i = 0; i < 5; ++i) {
int value{};
q.pop(value);
}
}两个线程分别运行 producer 与 consumer,为了观测运行我们可以为 push 与 pop 中增加打印语句:
std::cout << "push:" << new_value << std::endl;
std::cout << "pop:" << value << std::endl;可能的运行结果是:
push:0
pop:0
push:1
pop:1
push:2
push:3
push:4
pop:2
pop:3
pop:4这很正常,到底哪个线程会抢到 CPU 时间片持续运行,是系统调度决定的,我们只需要保证一开始提到的两点就行了:
push与pop都只能单独执行;当队列为空时,不执行pop操作。
我们可以给一个简单的示意图帮助你理解这段运行结果:
初始状态:队列为空
+---+---+---+---+---+
Producer 线程插入元素 0:
+---+---+---+---+---+
| 0 | | | | |
Consumer 线程弹出元素 0:
+---+---+---+---+---+
| | | | | |
Producer 线程插入元素 1:
+---+---+---+---+---+
| 1 | | | | |
Consumer 线程弹出元素 1:
+---+---+---+---+---+
| | | | | |
Producer 线程插入元素 2:
+---+---+---+---+---+
| | 2 | | | |
Producer 线程插入元素 3:
+---+---+---+---+---+
| | 2 | 3 | | |
Producer 线程插入元素 4:
+---+---+---+---+---+
| | 2 | 3 | 4 | |
Consumer 线程弹出元素 2:
+---+---+---+---+---+
| | | 3 | 4 | |
Consumer 线程弹出元素 3:
+---+---+---+---+---+
| | | | 4 | |
Consumer 线程弹出元素 4:
+---+---+---+---+---+
| | | | | |
队列为空,所有元素已被弹出到此,也就可以了。
使用条件变量实现后台提示音播放
一个常见的场景是:当你的软件完成了主要功能后,领导可能突然要求添加一些竞争对手产品的功能。比如领导看到了人家的设备跑起来总是有一些播报,说明当前的情况,执行的过程,或者报错了也会有提示音说明。于是就想让我们的程序也增加“语音提示”的功能。此时,你需要考虑如何在程序运行到不同状态时添加适当的语音播报,并且确保这些提示音的播放不会影响其他功能的正常运行。
为了不影响程序的流畅执行,提示音的播放显然不能占据业务线程的资源。我们需要额外启动一个线程来专门处理这个任务。
但是,大多数的提示音播放都是短暂且简单。如果每次播放提示音时都新建一个线程,且不说创建线程也需要大量时间,可能影响业务正常的执行任务的流程,就光是其频繁创建线程的开销也是不能接受的。
因此,更合理的方案是:在程序启动时,就启动一个专门用于播放提示音的线程。当没有需要播放的提示时,该线程会一直处于等待状态;一旦有提示音需要播放,线程就被唤醒,完成播放任务。
具体来说,我们可以通过条件变量来实现这一逻辑,核心是监控一个音频队列。我们可以封装一个类型,包含以下功能:
- 一个成员函数在对象构造时就启动,使用条件变量监控队列是否为空,互斥量确保共享资源的同步。如果队列中有任务,就取出并播放提示音;如果队列为空,则线程保持阻塞状态,等待新的任务到来。
- 提供一个外部函数,以供在需要播放提示音的时候调用它,向队列添加新的元素,该函数需要通过互斥量来保护数据一致性,并在成功添加任务后唤醒条件变量,通知播放线程执行任务。
这种设计通过合理利用条件变量和互斥量,不仅有效减少了 CPU 的无效开销,还能够确保主线程的顺畅运行。它不仅适用于提示音的播放,还能扩展用于其他类似的后台任务场景。
我们引入 SFML 三方库进行声音播放,然后再自己进行上层封装。
class AudioPlayer {
public:
AudioPlayer() : stop{ false }, player_thread{ &AudioPlayer::playMusic, this }
{}
~AudioPlayer() {
// 等待队列中所有音乐播放完毕
while (!audio_queue.empty()) {
std::this_thread::sleep_for(50ms);
}
stop = true;
cond.notify_all();
if (player_thread.joinable()) {
player_thread.join();
}
}
void addAudioPath(const std::string& path) {
std::lock_guard<std::mutex> lock{ mtx }; // 互斥量确保了同一时间不会有其它地方在操作共享资源(队列)
audio_queue.push(path); // 为队列添加元素 表示有新的提示音需要播放
cond.notify_one(); // 通知线程新的音频
}
private:
void playMusic() {
while (!stop) {
std::string path;
{
std::unique_lock<std::mutex> lock{ mtx };
cond.wait(lock, [this] { return !audio_queue.empty() || stop; });
if (audio_queue.empty()) return; // 防止在对象为空时析构出错
path = audio_queue.front(); // 从队列中取出元素
audio_queue.pop(); // 取出后就删除元素,表示此元素已被使用
}
if (!music.openFromFile(path)) {
std::cerr << "无法加载音频文件: " << path << std::endl;
continue; // 继续播放下一个音频
}
music.play();
// 等待音频播放完毕
while (music.getStatus() == sf::SoundSource::Playing) {
sf::sleep(sf::seconds(0.1f)); // sleep 避免忙等占用 CPU
}
}
}
std::atomic<bool> stop; // 控制线程的停止与退出,
std::thread player_thread; // 后台执行音频任务的专用线程
std::mutex mtx; // 保护共享资源
std::condition_variable cond; // 控制线程等待和唤醒,当有新任务时通知音频线程
std::queue<std::string> audio_queue; // 音频任务队列,存储待播放的音频文件路径
sf::Music music; // SFML 音频播放器,用于加载和播放音频文件
};该代码实现了一个简单的后台音频播放类型,通过条件变量和互斥量确保播放线程 playMusic 只在只在有音频任务需要播放时工作(当外部通过调用 addAudioPath() 向队列添加播放任务时)。在没有任务时,线程保持等待状态,避免占用 CPU 资源影响主程序的运行。
注意
其实这段代码还存在着一个初始化顺序导致的问题,见 #27
此外,关于提示音的播报,为了避免每次都手动添加路径,我们可以创建一个音频资源数组,便于使用:
static constexpr std::array soundResources{
"./sound/01初始化失败.ogg",
"./sound/02初始化成功.ogg",
"./sound/03试剂不足,请添加.ogg",
"./sound/04试剂已失效,请更新.ogg",
"./sound/05清洗液不足,请添加.ogg",
"./sound/06废液桶即将装满,请及时清空.ogg",
"./sound/07废料箱即将装满,请及时清空.ogg",
"./sound/08激发液A液不足,请添加.ogg",
"./sound/09激发液B液不足,请添加.ogg",
"./sound/10反应杯不足,请添加.ogg",
"./sound/11检测全部完成.ogg"
};为了提高代码的可读性,我们还可以使用一个枚举类型来表示音频资源的索引:
enum SoundIndex {
InitializationFailed,
InitializationSuccessful,
ReagentInsufficient,
ReagentExpired,
CleaningAgentInsufficient,
WasteBinAlmostFull,
WasteContainerAlmostFull,
LiquidAInsufficient,
LiquidBInsufficient,
ReactionCupInsufficient,
DetectionCompleted,
SoundCount // 总音频数量,用于计数
};注
需要注意的是 SFML不支持 .mp3 格式的音频文件,大家可以使用 ffmpeg 或者其它软件网站将音频转换为支持的格式。
SFML 自 2.6 版本开始通过 minimp3 支持 .mp3 格式的音频文件。不过新版本的 SFML 也要求更高版本的工具链。
如果只是为了播放 .mp3 的音乐,也可以直接使用 minimp3 。
如果是测试使用,不知道去哪生成这些语音播报,我们推荐 tts-vue。
我们的代码也可以在 Linux 中运行,并且整体仅需 C++11 标准(除了
soundResources数组)。
SFML 依赖于 FLAC 和 OpenAL 这两个库。官网上下载的 windows 版本的 SFML 已包含这些依赖,但在 Linux 上需要用户自行下载并安装它们。如:sudo apt-get install libflac-dev sudo apt-get install libopenal-dev
提示
这种设计思路非常常见。例如,USBMonitor-cpp 是一个跨平台的 C++ 库,用于监测 U 盘插拔状态变化。感兴趣的话可以参考该项目,进一步学习和实践。
使用 future
举个例子:我们在车站等车,你可能会做一些别的事情打发时间,比如学习现代 C++ 模板教程、观看 mq白 的视频教程、玩手机等。不过,你始终在等待一件事情:车到站。
C++ 标准库将这种事件称为 future。它用于处理线程中需要等待某个事件的情况,线程知道预期结果。等待的同时也可以执行其它的任务。
C++ 标准库有两种 future,都声明在 <future> 头文件中:独占的 std::future 、共享的 std::shared_future。它们的区别与 std::unique_ptr 和 std::shared_ptr 类似。std::future 只能与单个指定事件关联,而 std::shared_future 能关联多个事件。它们都是模板,它们的模板类型参数,就是其关联的事件(函数)的返回类型。当多个线程需要访问一个独立 future 对象时, 必须使用互斥量或类似同步机制进行保护。而多个线程访问同一共享状态,若每个线程都是通过其自身的 shared_future 对象副本进行访问,则是安全的。
最简单有效的使用是,我们先前讲的 std::thread 在线程中执行任务是没有返回值的,这个问题就能使用 future 解决。
创建异步任务获取返回值
假设需要执行一个耗时任务并获取其返回值,但是并不急切的需要它。那么就可以启动新线程计算,然而 std::thread 没提供直接从线程获取返回值的机制。所以我们可以使用 std::async 函数模板。
使用 std::async 启动一个异步任务,它会返回一个 std::future 对象,这个对象和任务关联,将持有最终计算出来的结果。当需要任务执行完的结果的时候,只需要调用 get() 成员函数,就会阻塞直到 future 为就绪为止(即任务执行完毕),返回执行结果。valid() 成员函数检查 future 当前是否关联共享状态,即是否当前关联任务。还未关联,或者任务已经执行完(调用了 get()、set()),都会返回 false。
#include <iostream>
#include <thread>
#include <future> // 引入 future 头文件
int task(int n) {
std::cout << "异步任务 ID: " << std::this_thread::get_id() << '\n';
return n * n;
}
int main() {
std::future<int> future = std::async(task, 10);
std::cout << "main: " << std::this_thread::get_id() << '\n';
std::cout << std::boolalpha << future.valid() << '\n'; // true
std::cout << future.get() << '\n';
std::cout << std::boolalpha << future.valid() << '\n'; // false
}运行测试。
与 std::thread 一样,std::async 支持任意可调用(Callable)对象,以及传递调用参数。包括支持使用 std::ref ,以及支持只能移动的类型。我们下面详细聊一下 std::async 参数传递的事。
struct X{
int operator()(int n)const{
return n * n;
}
};
struct Y{
int f(int n)const{
return n * n;
}
};
void f(int& p) { std::cout << &p << '\n'; }
int main(){
Y y;
int n = 0;
auto t1 = std::async(X{}, 10);
auto t2 = std::async(&Y::f,&y,10);
auto t3 = std::async([] {});
auto t4 = std::async(f, std::ref(n));
std::cout << &n << '\n';
}运行测试。
如你所见,它支持所有可调用(Callable)对象,并且也是默认按值复制,必须使用 std::ref 才能传递引用。并且它和 std::thread 一样,内部会将保有的参数副本转换为右值表达式进行传递,这是为了那些只支持移动的类型,左值引用没办法引用右值表达式,所以如果不使用 std::ref,这里 void f(int&) 就会导致编译错误,如果是 void f(const int&) 则可以通过编译,不过引用的不是我们传递的局部对象。
void f(const int& p) {}
void f2(int& p ){}
int n = 0;
std::async(f, n); // OK! 可以通过编译,不过引用的并非是局部的n
std::async(f2, n); // Error! 无法通过编译我们来展示使用 std::move ,也就是移动传递参数并接受返回值:
struct move_only{
move_only() { std::puts("默认构造"); }
move_only(move_only&&)noexcept { std::puts("移动构造"); }
move_only& operator=(move_only&&) noexcept {
std::puts("移动赋值");
return *this;
}
move_only(const move_only&) = delete;
};
move_only task(move_only x){
std::cout << "异步任务 ID: " << std::this_thread::get_id() << '\n';
return x;
}
int main(){
move_only x;
std::future<move_only> future = std::async(task, std::move(x));
std::this_thread::sleep_for(std::chrono::seconds(1));
std::cout << "main\n";
move_only result = future.get(); // 等待异步任务执行完毕
}运行测试。
如你所见,它支持只移动类型,我们将参数使用 std::move 传递,接收参数的时候直接调用 get 函数即可。
接下来我们聊 std::async 的执行策略,我们前面一直没有使用,其实就是在传递可调用对象与参数之前传递枚举值罢了:
std::launch::async在不同线程上执行异步任务。std::launch::deferred惰性求值,不创建线程,等待future对象调用wait或get成员函数的时候执行任务。
而我们先前一直没有写明这个参数,是因为 std::async 函数模板有两个重载,不给出执行策略就是以:std::launch::async | std::launch::deferred 调用另一个重载版本(这一点中在源码中很明显),此策略表示由实现选择到底是否创建线程执行异步任务。典型情况是,如果系统资源充足,并且异步任务的执行不会导致性能问题,那么系统可能会选择在新线程中执行任务。但是,如果系统资源有限,或者延迟执行可以提高性能或节省资源,那么系统可能会选择延迟执行。
如果你阅读
libstdc++的代码,会发现的确如此。然而值得注意的是,在 MSVC STL 的实现中,
launch::async | launch::deferred与launch::async执行策略毫无区别,源码如下:template <class _Ret, class _Fty> _Associated_state<typename _P_arg_type<_Ret>::type>* _Get_associated_state(launch _Psync, _Fty&& _Fnarg) { // construct associated asynchronous state object for the launch type switch (_Psync) { // select launch type case launch::deferred: return new _Deferred_async_state<_Ret>(_STD forward<_Fty>(_Fnarg)); case launch::async: // TRANSITION, fixed in vMajorNext, should create a new thread here default: return new _Task_async_state<_Ret>(_STD forward<_Fty>(_Fnarg)); } }且
_Task_async_state会通过::Concurrency::create_task[1] 从线程池中获取线程并执行任务返回包装对象。简而言之,使用
std::async,只要不是launch::deferred策略,那么 MSVC STL 实现中都是必然在线程中执行任务。因为是线程池,所以执行新任务是否创建新线程,任务执行完毕线程是否立即销毁,不确定。
我们来展示一下:
void f(){
std::cout << std::this_thread::get_id() << '\n';
}
int main(){
std::cout << std::this_thread::get_id() << '\n';
auto f1 = std::async(std::launch::deferred, f);
f1.wait(); // 在 wait() 或 get() 调用时执行,不创建线程
auto f2 = std::async(std::launch::async,f); // 创建线程执行异步任务
auto f3 = std::async(std::launch::deferred | std::launch::async, f); // 实现选择的执行方式
}运行测试。
其实到此基本就差不多了,我们再介绍两个常见问题即可:
如果从
std::async获得的std::future没有被移动或绑定到引用,那么在完整表达式结尾,std::future的**析构函数将阻塞,直到到异步任务完成**。因为临时对象的生存期就在这一行,而对象生存期结束就会调用调用析构函数。std::async(std::launch::async, []{ f(); }); // 临时量的析构函数等待 f() std::async(std::launch::async, []{ g(); }); // f() 完成前不开始如你所见,这并不能创建异步任务,它会阻塞,然后逐个执行。
被移动的
std::future没有所有权,失去共享状态,不能调用get、wait成员函数。auto t = std::async([] {}); std::future<void> future{ std::move(t) }; t.wait(); // Error! 抛出异常如同没有线程资源所有权的
std::thread对象调用join()一样错误,这是移动语义的基本语义逻辑。
future 与 std::packaged_task
类模板 std::packaged_task 包装任何可调用(Callable)目标(函数、lambda 表达式、bind 表达式或其它函数对象),使得能异步调用它。其返回值或所抛异常被存储于能通过 std::future 对象访问的共享状态中。
通常它会和 std::future 一起使用,不过也可以单独使用,我们一步一步来:
std::packaged_task<double(int, int)> task([](int a, int b){
return std::pow(a, b);
});
task(10, 2); // 执行传递的 lambda,但无法获取返回值它有 operator() 的重载,它会执行我们传递的可调用(Callable)对象,不过这个重载的返回类型是 void 没办法获取返回值。
如果想要异步的获取返回值,我们需要在调用 operator() 之前,让它和 future 关联,然后使用 future.get(),也就是:
std::packaged_task<double(int, int)> task([](int a, int b){
return std::pow(a, b);
});
std::future<double>future = task.get_future();
task(10, 2); // 此处执行任务
std::cout << future.get() << '\n'; // 不阻塞,此处获取返回值运行测试。
先关联任务,再执行任务,当我们想要获取任务的返回值的时候,就 future.get() 即可。值得注意的是,任务并不会在线程中执行,想要在线程中执行异步任务,然后再获取返回值,我们可以这么做:
std::packaged_task<double(int, int)> task([](int a, int b){
return std::pow(a, b);
});
std::future<double> future = task.get_future();
std::thread t{ std::move(task),10,2 }; // 任务在线程中执行
// todo.. 幻想还有许多耗时的代码
t.join();
std::cout << future.get() << '\n'; // 并不阻塞,获取任务返回值罢了运行测试。
因为 task 本身是重载了 operator() 的,是可调用对象,自然可以传递给 std::thread 执行,以及传递调用参数。唯一需要注意的是我们使用了 std::move ,这是因为 std::packaged_task 只能移动,不能复制。
简而言之,其实 std::packaged_task 也就是一个“包装”类而已,它本身并没什么特殊的,老老实实执行我们传递的任务,且方便我们获取返回值罢了,明确这一点,那么一切都不成问题。
std::packaged_task 也可以在线程中传递,在需要的时候获取返回值,而非像上面那样将它自己作为可调用对象:
template<typename R, typename...Ts, typename...Args>
requires std::invocable<std::packaged_task<R(Ts...)>&, Args...>
void async_task(std::packaged_task<R(Ts...)>& task, Args&&...args) {
// todo..
task(std::forward<Args>(args)...);
}
int main() {
std::packaged_task<int(int,int)> task([](int a,int b){
return a + b;
});
int value = 50;
std::future<int> future = task.get_future();
// 创建一个线程来执行异步任务
std::thread t{ [&] {async_task(task, value, value); } };
std::cout << future.get() << '\n';
t.join();
}运行测试。
我们套了一个 lambda,这是因为函数模板不是函数,它并非具体类型,没办法直接被那样传递使用,只能包一层了。这只是一个简单的示例,展示可以使用 std::packaged_task 作函数形参,然后我们来传递任务进行异步调用等操作。
我们再将第二章实现的并行 sum 改成 std::package_task + std::future 的形式:
template<typename ForwardIt>
auto sum(ForwardIt first, ForwardIt last) {
using value_type = std::iter_value_t<ForwardIt>;
std::size_t num_threads = std::thread::hardware_concurrency();
std::ptrdiff_t distance = std::distance(first, last);
if (distance > 1024000) {
// 计算每个线程处理的元素数量
std::size_t chunk_size = distance / num_threads;
std::size_t remainder = distance % num_threads;
// 存储每个线程要执行的任务
std::vector<std::packaged_task<value_type()>> tasks;
// 和每一个任务进行关联的 future 用于获取返回值
std::vector<std::future<value_type>> futures(num_threads);
// 存储关联线程的线程对象
std::vector<std::thread> threads;
// 制作任务、与 future 关联、启动线程执行
auto start = first;
for (std::size_t i = 0; i < num_threads; ++i) {
auto end = std::next(start, chunk_size + (i < remainder ? 1 : 0));
tasks.emplace_back(std::packaged_task<value_type()>{[start, end, i] {
return std::accumulate(start, end, value_type{});
}});
start = end; // 开始迭代器不断向前
futures[i] = tasks[i].get_future(); // 任务与 std::future 关联
threads.emplace_back(std::move(tasks[i]));
}
// 等待所有线程执行完毕
for (auto& thread : threads)
thread.join();
// 汇总线程的计算结果
value_type total_sum {};
for (std::size_t i = 0; i < num_threads; ++i) {
total_sum += futures[i].get();
}
return total_sum;
}
value_type total_sum = std::accumulate(first, last, value_type{});
return total_sum;
}运行测试。
相比于之前,其实不同无非是定义了 std::vector<std::packaged_task<value_type()>> tasks 与 std::vector<std::future<value_type>> futures ,然后在循环中制造任务插入容器,关联 future,再放到线程中执行。最后汇总的时候写一个循环,futures[i].get() 获取任务的返回值加起来即可。
到此,也就可以了。
使用 std::promise
类模板 std::promise 用于存储一个值或一个异常,之后通过 std::promise 对象所创建的 std::future 对象异步获得。
// 计算函数,接受一个整数并返回它的平方
void calculate_square(std::promise<int> promiseObj, int num) {
// 模拟一些计算
std::this_thread::sleep_for(std::chrono::seconds(1));
// 计算平方并设置值到 promise 中
promiseObj.set_value(num * num);
}
// 创建一个 promise 对象,用于存储计算结果
std::promise<int> promise;
// 从 promise 获取 future 对象进行关联
std::future<int> future = promise.get_future();
// 启动一个线程进行计算
int num = 5;
std::thread t(calculate_square, std::move(promise), num);
// 阻塞,直到结果可用
int result = future.get();
std::cout << num << " 的平方是:" << result << std::endl;
t.join();运行测试。
我们在新线程中通过调用 set_value() 函数设置 promise 的值,并在主线程中通过与其关联的 future 对象的 get() 成员函数获取这个值,如果promise的值还没有被设置,那么将阻塞当前线程,直到被设置为止。同样的 std::promise 只能移动,不可复制,所以我们使用了 std::move 进行传递。
除了 set_value() 函数外,std::promise 还有一个 set_exception() 成员函数,它接受一个 std::exception_ptr 类型的参数,这个参数通常通过 std::current_exception() 获取,用于指示当前线程中抛出的异常。然后,std::future 对象通过 get() 函数获取这个异常,如果 promise 所在的函数有异常被抛出,则 std::future 对象会重新抛出这个异常,从而允许主线程捕获并处理它。
void throw_function(std::promise<int> prom) {
try {
throw std::runtime_error("一个异常");
}
catch (...) {
prom.set_exception(std::current_exception());
}
}
int main() {
std::promise<int> prom;
std::future<int> fut = prom.get_future();
std::thread t(throw_function, std::move(prom));
try {
std::cout << "等待线程执行,抛出异常并设置\n";
fut.get();
}
catch (std::exception& e) {
std::cerr << "来自线程的异常: " << e.what() << '\n';
}
t.join();
}运行结果:
等待线程执行,抛出异常并设置
来自线程的异常: 一个异常你可能对这段代码还有一些疑问:我们写的是 promise<int> ,但是却没有使用 set_value 设置值,你可能会想着再写一行 prom.set_value(0)?
共享状态的 promise 已经存储值或者异常,再次调用 set_value(set_exception) 会抛出 std::future_error 异常,将错误码设置为 promise_already_satisfied。这是因为 std::promise 对象只能是存储值或者异常其中一种,而无法共存。
简而言之,set_value 与 set_exception 二选一,如果先前调用了 set_value ,就不可再次调用 set_exception,反之亦然(不然就会抛出异常),示例如下:
void throw_function(std::promise<int> prom) {
prom.set_value(100);
try {
throw std::runtime_error("一个异常");
}
catch (...) {
try{
// 共享状态的 promise 已存储值,调用 set_exception 产生异常
prom.set_exception(std::current_exception());
}catch (std::exception& e){
std::cerr << "来自 set_exception 的异常: " << e.what() << '\n';
}
}
}
int main() {
std::promise<int> prom;
std::future<int> fut = prom.get_future();
std::thread t(throw_function, std::move(prom));
std::cout << "等待线程执行,抛出异常并设置\n";
std::cout << "值:" << fut.get() << '\n'; // 100
t.join();
}运行结果:
等待线程执行,抛出异常并设置
值:100
来自 set_exception 的异常: promise already satisfiedfuture 的状态变化
需要注意的是,future 是一次性的,所以你需要注意移动。并且,调用 get 函数后,future 对象也会失去共享状态。
- 移动语义:这一点很好理解并且常见,因为移动操作标志着所有权的转移,意味着
future不再拥有共享状态(如之前所提到)。get和wait函数要求future对象拥有共享状态,否则会抛出异常。 - 共享状态失效:调用
get成员函数时,future对象必须拥有共享状态,但调用完成后,它就会失去共享状态,不能再次调用get。这是我们在本节需要特别讨论的内容。
std::future<void>future = std::async([] {});
std::cout << std::boolalpha << future.valid() << '\n'; // true
future.get();
std::cout << std::boolalpha << future.valid() << '\n'; // false
try {
future.get(); // 抛出 future_errc::no_state 异常
}
catch (std::exception& e) {
std::cerr << e.what() << '\n';
}运行测试。
这个问题在许多文档中没有明确说明,但通过阅读源码(MSVC STL),可以很清楚地理解:
// std::future<void>
void get() {
// block until ready then return or throw the stored exception
future _Local{_STD move(*this)};
_Local._Get_value();
}
// std::future<T>
_Ty get() {
// block until ready then return the stored result or throw the stored exception
future _Local{_STD move(*this)};
return _STD move(_Local._Get_value());
}
// std::future<T&>
_Ty& get() {
// block until ready then return the stored result or throw the stored exception
future _Local{_STD move(*this)};
return *_Local._Get_value();
}如上所示,我们展示了 std::future 的所有特化中 get 成员函数的实现。注意到了吗?尽管我们可能不了解移动构造函数的具体实现,但根据通用的语义,可以看出 future _Local{_STD move(*this)}; 将当前对象的共享状态转移给了这个局部对象,而局部对象在函数结束时析构。这意味着当前对象失去共享状态,并且状态被完全销毁。
另外一提,std::future<T> 这个特化,它 return std::move 是为了支持只能移动的类型能够使用 get 返回值,参见前文的 move_only 类型。
如果需要进行多次 get 调用,可以考虑使用下文提到的 std::shared_future。
多个线程的等待 std::shared_future
之前的例子中我们一直使用 std::future,但 std::future 有一个局限:future 是一次性的,它的结果只能被一个线程获取。get() 成员函数只能调用一次,当结果被某个线程获取后,std::future 就无法再用于其他线程。
int task(){
// todo..
return 10;
}
void thread_functio(std::future<int>& fut){
// todo..
int result = fut.get();
std::cout << result << '\n';
// todo..
}
int main(){
auto future = std::async(task); // 启动耗时的异步任务
// 可能有多个线程都需要此任务的返回值,于是我们将与其关联的 future 对象的引入传入
std::thread t{ thread_functio,std::ref(future) };
std::thread t2{ thread_functio,std::ref(future) };
t.join();
t2.join();
}可能有多个线程都需要耗时的异步任务的返回值,于是我们将与其关联的 future 对象的引入传给线程对象,让它能在需要的时候获取。
但是这存在个问题,future 是一次性的,只能被调用一次
get()成员函数,所以以上代码存在问题。
此时就需要使用 std::shared_future 来替代 std::future 了。std::future 与 std::shared_future 的区别就如同 std::unique_ptr、std::shared_ptr 一样。
std::future 是只能移动的,其所有权可以在不同的对象中互相传递,但只有一个对象可以获得特定的同步结果。而 std::shared_future 是可复制的,多个对象可以指代同一个共享状态。
在多个线程中对同一个 std::shared_future 对象进行操作时(如果没有进行同步保护)存在条件竞争。而从多个线程访问同一共享状态,若每个线程都是通过其自身的 shared_future 对象副本进行访问,则是安全的。
std::string fetch_data() {
std::this_thread::sleep_for(std::chrono::seconds(1)); // 模拟耗时操作
return "从网络获取的数据!";
}
int main() {
std::future<std::string> future_data = std::async(std::launch::async, fetch_data);
// // 转移共享状态,原来的 future 被清空 valid() == false
std::shared_future<std::string> shared_future_data = future_data.share();
// 第一个线程等待结果并访问数据
std::thread thread1([&shared_future_data] {
std::cout << "线程1:等待数据中..." << std::endl;
shared_future_data.wait();
std::cout << "线程1:收到数据:" << shared_future_data.get() << std::endl;
});
// 第二个线程等待结果并访问数据
std::thread thread2([&shared_future_data] {
std::cout << "线程2:等待数据中..." << std::endl;
shared_future_data.wait();
std::cout << "线程2:收到数据:" << shared_future_data.get() << std::endl;
});
thread1.join();
thread2.join();
}这段代码存在数据竞争,就如同我们先前所说:“在多个线程中对同一个 std::shared_future 对象进行操作时(如果没有进行同步保护)存在条件竞争”,它并没有提供线程安全的方式。而我们的 lambda 是按引用传递,也就是“同一个”进行操作了。可以改为:
std::string fetch_data() {
std::this_thread::sleep_for(std::chrono::seconds(1)); // 模拟耗时操作
return "从网络获取的数据!";
}
int main() {
std::future<std::string> future_data = std::async(std::launch::async, fetch_data);
std::shared_future<std::string> shared_future_data = future_data.share();
std::thread thread1([shared_future_data] {
std::cout << "线程1:等待数据中..." << std::endl;
shared_future_data.wait();
std::cout << "线程1:收到数据:" << shared_future_data.get() << std::endl;
});
std::thread thread2([shared_future_data] {
std::cout << "线程2:等待数据中..." << std::endl;
shared_future_data.wait();
std::cout << "线程2:收到数据:" << shared_future_data.get() << std::endl;
});
thread1.join();
thread2.join();
}这样访问的就都是 std::shared_future 的副本了,我们的 lambda 按复制捕获 std::shared_future 对象,每个线程都有一个 shared_future 的副本,这样不会有任何问题。这一点和 std::shared_ptr 类似[2]。
std::promise 也同,它的 get_future() 成员函数一样可以用来构造 std::shared_future,虽然它的返回类型是 std::future,不过不影响,这是因为 std::shared_future 有一个 std::future<T>&& 参数的构造函数,转移 std::future 的所有权。
std::promise<std::string> p;
std::shared_future<std::string> sf{ p.get_future() }; // 隐式转移所有权就不需要再强调了。
限时等待
阻塞调用会将线程挂起一段(不确定的)时间,直到对应的事件发生。通常情况下,这样的方式很好,但是在一些情况下,需要限定线程等待的时间,因为无限期地等待事件发生可能会导致性能下降或资源浪费。一个常见的例子是在很多网络库中的 connect 函数,这个函数调用是阻塞的,但是也是限时的,一定时间内没有连接到服务器就不会继续阻塞了,会进行其它处理,比如抛出异常。
介绍两种指定超时的方式,一种是“时间段”,另一种是“时间点”,其实就是先前讲的 std::this::thread::sleep_for 与 std::this_thread::sleep_until 的区别。前者是需要指定等待一段时间(比如 10 毫秒)。而后者是指定等待到一个具体的时间点(比如到 2024-05-07T12:01:10.123)。多数函数都对两种超时方式进行处理。处理持续时间的函数以 _for 作为后缀,处理绝对时间的函数以 _until 作为后缀。
条件变量 std::condition_variable 的等待函数,也有两个超时的版本 wait_for 和 wait_until 。它们和我们先前讲的 wait 成员函数一样有两个重载,可以选择是否传递一个谓词。它们相比于 wait 多了一个解除阻塞的可能,即:超过指定的时长或抵达指定的时间点。
在讲述它的使用细节之前,我们还是要来先聊一下 C++ 中的时间库(chrono),指定时间的方式,它较为麻烦。我们分:时钟(clock)、时间段(duration)、*时间点(time point)*三个阶段稍微介绍一下。
时钟
在 C++ 标准库中,时钟被视为时间信息的来源。C++ 定义了很多种时间类型,每种时钟类型都提供了四种不同的信息:
- 当前时间
- 时间类型
- 时钟节拍
- 稳定时钟
当前时间可以通过静态成员函数 now 获取,例如,std::chrono::system_clock::now() 会返回系统的当前时间。特定的时间点则可以通过 time_point 来指定。system_clock::now() 的返回类型就是 time_point。
时钟节拍被指定为 1/x(x 在不同硬件上有不同的值)秒,这是由时间周期所决定。假设一个时钟一秒有 25 个节拍,因此一个周期为 std::ratio<1,25> 。当一个时钟的时钟节拍每 2.5 秒一次,周期就可以表示为 std::ratio<5,2>。
类模板 std::chrono::duration 表示时间间隔。
template<class Rep, class Period = std::ratio<1>>
class duration;
std::ratio是一个分数类模板,它有两个非类型模板参数,也就是分子与分母,分母有默认实参 1,所以std::ratio<1>等价于std::ratio<1,1>。
如你所见,它默认的时钟节拍是 1,这是一个很重要的类,标准库通过它定义了很多的时间类型,比如 std::chrono::minutes 是分钟类型,那么它的 Period 就是 std::ratio<60> ,因为一分钟等于 60 秒。
using minutes = duration<int, ratio<60>>;稳定时钟(Steady Clock)是指提供稳定、持续递增的时间流逝信息的时钟。它的特点是不受系统时间调整或变化的影响,即使在系统休眠或时钟调整的情况下,它也能保持稳定。在 C++ 标准库中,std::chrono::steady_clock 就是一个稳定时钟。它通常用于测量时间间隔和性能计时等需要高精度和稳定性的场景。可以通过 is_steady 静态常量判断当前时钟是否是稳定时钟。
稳定时钟的主要优点在于,它可以提供相对于起始时间的稳定的递增时间,因此适用于需要保持时间顺序和不受系统时间变化影响的应用场景。相比之下,像 std::chrono::system_clock 这样的系统时钟可能会受到系统时间调整或变化的影响,因此在某些情况下可能不适合对时间间隔进行精确测量。
不管使用哪种时钟获取时间,C++ 都提供了函数,可以将时间点转换为 time_t 类型的值:
auto now = std::chrono::system_clock::now();
time_t now_time = std::chrono::system_clock::to_time_t(now);
std::cout << "Current time:\t" << std::put_time(std::localtime(&now_time), "%H:%M:%S\n");
auto now2 = std::chrono::steady_clock::now();
now_time = std::chrono::system_clock::to_time_t(now);
std::cout << "Current time:\t" << std::put_time(std::localtime(&now_time), "%H:%M:%S\n");C++ 的时间库极其繁杂,主要在于类型之多,以及实现之复杂。根据我们的描述,了解基本构成、概念、使用,即可。
时间段
时间部分最简单的就是时间段,主要的内容就是我们上面讲的类模板 std::chrono::duration ,它用于对时间段进行处理。
它的第一个参数是类型表示,第二个参数就是先前提到的“节拍”,需要传递一个 std::ratio 类型,也就是一个时钟所用的秒数。
标准库在 std::chrono 命名空间内为时间段提供了一系列的类型,它们都是通过 std::chrono::duration 定义的别名:
using nanoseconds = duration<long long, nano>;
using microseconds = duration<long long, micro>;
using milliseconds = duration<long long, milli>;
using seconds = duration<long long>;
using minutes = duration<int, ratio<60>>;
using hours = duration<int, ratio<3600>>;
// CXX20
using days = duration<int, ratio_multiply<ratio<24>, hours::period>>;
using weeks = duration<int, ratio_multiply<ratio<7>, days::period>>;
using years = duration<int, ratio_multiply<ratio<146097, 400>, days::period>>;
using months = duration<int, ratio_divide<years::period, ratio<12>>>;如果没有指明 duration 的第二个非类型模板参数,那么代表默认 std::ratio<1>,比如 seconds 也就是一秒。
如上,是 MSVC STL 定义的,看似有一些没有使用 ratio 作为第二个参数,其实也还是别名罢了,见:
using milli = ratio<1, 1000>; // 千分之一秒,也就是一毫秒了并且为了方便使用,在 C++14 标准库增加了时间字面量,存在于 std::chrono_literals 命名空间中,让我们得以简单的使用:
using namespace std::chrono_literals;
auto one_nanosecond = 1ns;
auto one_microsecond = 1us;
auto one_millisecond = 1ms;
auto one_second = 1s;
auto one_minute = 1min;
auto one_hour = 1h;当不要求截断值的情况下(时转换为秒时没问题的,但反过来不行)时间段有隐式转换,显式转换可以由 std::chrono::duration_cast<> 来完成。
std::chrono::milliseconds ms{ 3999 };
std::chrono::seconds s = std::chrono::duration_cast<std::chrono::seconds>(ms);
std::cout << s.count() << '\n';这里的结果是截断的,而不会进行所谓的四舍五入,3999 毫秒,也就是 3.999 秒最终的值是 3。
很多时候这并不是我们想要的,比如我们想要的其实是输出
3.999秒,而不是3秒 或者3999毫秒。seconds 是
duration<long long>这意味着它无法接受浮点数,我们直接改成duration<double>即可:std::chrono::duration<double> s = std::chrono::duration_cast<std::chrono::duration<double>>(ms);当然了,这样写很冗余,并且这种形式的转换是可以直接隐式的,也就是其实我们可以直接:
std::chrono::duration<double> s = ms;无需使用
duration_cast,可以直接隐式转换。另外我们用的
duration都是省略了ratio的,其实默认类型就是ratio<1>,代表一秒。参见源码声明:_EXPORT_STD template <class _Rep, class _Period = ratio<1>> class duration;
时间库支持四则运算,可以对两个时间段进行加减乘除。时间段对象可以通过 count() 成员函数获得计次数。例如 std::chrono::milliseconds{123}.count() 的结果就是 123。
基于时间段的等待都是由 std::chrono::duration<> 来完成。例如:等待一个 future 对象在 35 毫秒内变为就绪状态:
std::future<int> future = std::async([] {return 6; });
if (future.wait_for(35ms) == std::future_status::ready)
std::cout << future.get() << '\n';wait_for: 等待结果,如果在指定的超时间隔后仍然无法得到结果,则返回。它的返回类型是一个枚举类 std::future_status ,三个枚举项分别表示三种 future 状态。
deferred | 共享状态持有的函数正在延迟运行,结果将仅在明确请求时计算 |
|---|---|
ready | 共享状态就绪 |
timeout | 共享状态在经过指定的等待时间内仍未就绪 |
timeout 超时,也很好理解,那我们就提一下 deferred :
auto future = std::async(std::launch::deferred, []{});
if (future.wait_for(35ms) == std::future_status::deferred)
std::cout << "future_status::deferred " << "正在延迟执行\n";
future.wait(); // 在 wait() 或 get() 调用时执行,不创建线程时间点
时间点可用 std::chrono::time_point<> 来表示,第一个模板参数用来指定使用的时钟,第二个模板参数用来表示时间单位(std::chrono::duration<>)。时间点顾名思义就是时间中的一个点,在 C++ 中用于表达当前时间,先前提到的静态成员函数 now() 获取当前时间,它们的返回类型都是 std::chrono::time_point。
template<
class Clock,
class Duration = typename Clock::duration
> class time_point;如你所见,它的第二个模板参数是时间段,就是时间的间隔,其实也就可以理解为表示时间点的精度,默认是根据第一个参数时钟得到的,所以假设有类型:
std::chrono::time_point<std::chrono::system_clock>那它等价于:
std::chrono::time_point<std::chrono::system_clock, std::chrono::system_clock::duration>也就是说第二个参数的实际类型是:
std::chrono::duration<long long,std::ratio<1, 10000000>> // // 100 nanoseconds也就是说 std::chrono::time_point<std::chrono::system_clock> 的精度是 100 纳秒。
更多的问题参见源码都很直观。
注意,这里的精度并非是实际的时间精度。时间和硬件系统等关系极大,以 windows 为例:
Windows 内核中的时间间隔计时器默认每隔 15.6 毫秒触发一次中断。因此,如果你使用基于系统时钟的计时方法,默认情况下精度约为 15.6 毫秒。不可能达到纳秒级别。
由于这个系统时钟的限制,那些基于系统时钟的 API(例如
Sleep()、WaitForSingleObject()等)的最小睡眠时间默认就是 15.6 毫秒左右。如:
std::this_thread::sleep_for(std::chrono::milliseconds(1));不过我们也可以使用系统 API 调整系统时钟的精度,需要链接 windows 多媒体库
winmm.lib,然后使用 API:timeBeginPeriod(1); // 设置时钟精度为 1 毫秒 // todo.. timeEndPeriod(1); // 恢复默认精度
同样的,时间点也支持加减以及比较操作。
std::chrono::steady_clock::now() + std::chrono::nanoseconds(500); // 500 纳秒之后的时间可以减去一个时间点,结果是两个时间点的时间差。这对于代码块的计时是很有用的,如:
auto start = std::chrono::steady_clock::now();
std::this_thread::sleep_for(std::chrono::seconds(1));
auto end = std::chrono::steady_clock::now();
auto result = std::chrono::duration_cast<std::chrono::milliseconds>(end - start);
std::cout << result.count() << '\n';运行测试。
我们进行了一个显式的转换,最终输出的是以毫秒作为单位,有可能不会是 1000,没有这么精确。
等待条件变量满足条件——带超时功能
using namespace std::chrono_literals;
std::condition_variable cv;
bool done{};
std::mutex m;
bool wait_loop() {
const auto timeout = std::chrono::steady_clock::now() + 500ms;
std::unique_lock<std::mutex> lk{ m };
while (!done) {
if (cv.wait_until(lk, timeout) == std::cv_status::timeout) {
std::cout << "超时 500ms\n";
return false;
}
}
return true;
}运行测试。
_until 也就是等待到一个时间点,我们设置的是等待到当前时间往后 500 毫秒。如果超过了这个时间还没有被唤醒,那就打印超时,并退出循环,函数返回 false。
到此,时间点的知识也就足够了。
异步任务执行
在开发带有 UI 的程序时,主线程用于处理 UI 更新和用户交互,如果在主线程中执行耗时任务会导致界面卡顿。因此,需要使用异步任务来减轻主线程的压力。以下是一个使用 Qt 实现异步任务的示例,展示了如何在不阻塞 UI 线程的情况下执行耗时任务,并更新进度条。
背景介绍
在 Qt 中,GUI 控件通常只能在创建它们的线程中进行操作,因为它们是线程不安全的。我们可以使用 QMetaObject::invokeMethod 来跨线程调用主线程上的控件方法,从而在其他线程中安全地更新 UI 控件。以下代码示例展示了如何通过 QMetaObject::invokeMethod 确保 UI 控件的更新操作在主线程中执行。
void task(){
future = std::async(std::launch::async, [=] {
QMetaObject::invokeMethod(this, [this] {
button->setEnabled(false);
progressBar->setRange(0, 1000);
button->setText("正在执行...");
});
for (int i = 0; i < 1000; ++i) {
std::this_thread::sleep_for(10ms);
QMetaObject::invokeMethod(this, [this, i] {
progressBar->setValue(i);
});
}
QMetaObject::invokeMethod(this, [this] {
button->setText("start");
button->setEnabled(true);
});
});
}上面的代码创建了一个异步任务,并指明了执行策略。任务在线程中执行,不会阻塞 UI 线程。如果不这样做,界面将会卡顿(可以尝试将函数的第一行与最后一行注释掉以验证这一点)。
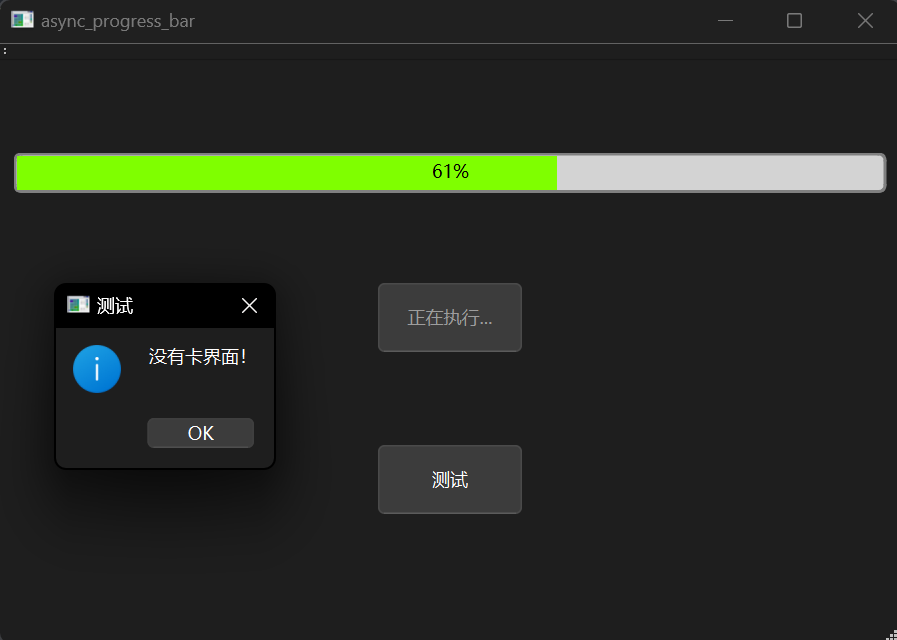
在启动进度条后,能够正常点击“测试”按钮并触发弹窗,说明 UI 没有被阻塞。相反,如果不使用线程,界面将会卡住,无法点击“测试”按钮或移动窗口。
项目说明
项目使用 Visual Studio + CMake,可以直接安装 Qt 插件后打开此项目。项目结构简单,所有界面与设置均通过代码控制,无需进行其他 UI 操作。只需关注 async_progress_bar.h、async_progress_bar.cpp 和 main.cpp 这三个文件,它们位于仓库的 code 文件夹中。
完整代码实现
class async_progress_bar : public QMainWindow{
Q_OBJECT
public:
async_progress_bar(QWidget *parent = nullptr);
~async_progress_bar();
void task(){
future = std::async(std::launch::async, [=] {
QMetaObject::invokeMethod(this, [this] {
// 这里显示的线程 ID 就是主线程,代表这些任务就是在主线程,即 UI 线程执行
QMessageBox::information(nullptr, "线程ID", std::to_string(_Thrd_id()).c_str());
button->setEnabled(false);
progress_bar->setRange(0, 1000);
button->setText("正在执行...");
});
for (int i = 0; i <= 1000; ++i) {
std::this_thread::sleep_for(10ms);
QMetaObject::invokeMethod(this, [this, i] {
progress_bar->setValue(i);
});
}
QMetaObject::invokeMethod(this, [this] {
button->setText("start");
button->setEnabled(true);
});
// 不在 invokeMethod 中获取线程 ID,这里显示的是子线程的ID
auto s = std::to_string(_Thrd_id());
QMetaObject::invokeMethod(this, [=] {
QMessageBox::information(nullptr, "线程ID", s.c_str());
});
});
}
private:
QString progress_bar_style =
"QProgressBar {"
" border: 2px solid grey;"
" border-radius: 5px;"
" background-color: lightgrey;"
" text-align: center;" // 文本居中
" color: #000000;" // 文本颜色
"}"
"QProgressBar::chunk {"
" background-color: #7FFF00;"
" width: 10px;" // 设置每个进度块的宽度
" font: bold 14px;" // 设置进度条文本字体
"}";
QString button_style =
"QPushButton {"
" text-align: center;" // 文本居中
"}";
QProgressBar* progress_bar{};
QPushButton* button{};
QPushButton* button2{};
Ui::async_progress_barClass ui{};
std::future<void>future;
};
// 创建控件 设置布局、样式 连接信号
async_progress_bar::async_progress_bar(QWidget *parent)
: QMainWindow{ parent }, progress_bar{ new QProgressBar(this) },
button{ new QPushButton("start",this) },button2{ new QPushButton("测试",this) } {
ui.setupUi(this);
progress_bar->setStyleSheet(progress_bar_style);
progress_bar->setRange(0, 1000);
button->setMinimumSize(100, 50);
button->setMaximumWidth(100);
button->setStyleSheet(button_style);
button->setSizePolicy(QSizePolicy::Minimum, QSizePolicy::Fixed);
button2->setMinimumSize(100, 50);
button2->setMaximumWidth(100);
button2->setStyleSheet(button_style);
button2->setSizePolicy(QSizePolicy::Minimum, QSizePolicy::Fixed);
QVBoxLayout* layout = new QVBoxLayout;
layout->addWidget(progress_bar);
layout->addWidget(button, 0, Qt::AlignHCenter);
layout->addWidget(button2, 0, Qt::AlignHCenter);
// 设置窗口布局为垂直布局管理器
centralWidget()->setLayout(layout);
connect(button, &QPushButton::clicked, this, &async_progress_bar::task);
connect(button2, &QPushButton::clicked, []{
QMessageBox::information(nullptr, "测试", "没有卡界面!");
});
}注意事项
QMetaObject::invokeMethod的 lambda 是在主线程运行的,通过显示的线程 ID 可以验证这一点。- 使用
std::async的std::launch::async参数强制异步执行任务,以确保任务在新线程中运行。
跨平台兼容性
C++11 的 std::this_thread::get_id() 返回的内部类 std::thread::id 没办法直接转换为 unsigned int,我们就直接使用了 win32 的 API _Thrd_id() 了。如果您是 Linux 之类的环境,使用 POSIX 接口 pthread_self()。
实践建议
这个例子其实很好的展示了多线程异步的作用,因为有 UI,所以很直观,毕竟如果你不用线程,那么不就卡界面了,用了就没事。
建议下载并运行此项目,通过实际操作理解代码效果。同时,可以尝试修改代码,观察不同情况下 UI 的响应情况,以加深对异步任务处理的理解。
C++20 信号量
C++20 引入了信号量,对于那些熟悉操作系统或其它并发支持库的开发者来说,这个同步设施的概念应该不会感到陌生。信号量源自操作系统,是一个古老而广泛应用的同步设施,在各种编程语言中都有自己的抽象实现。然而,C++ 标准库对其的支持却来得很晚,在 C++20 中才得以引入。
信号量是一个非常轻量简单的同步设施,它维护一个计数,这个计数不能小于 0。信号量提供两种基本操作:释放(增加计数)和等待(减少计数)。如果当前信号量的计数值为 0,那么执行“等待”操作的线程将会一直阻塞,直到计数大于 0,也就是其它线程执行了“释放”操作。
C++ 提供了两个信号量类型:std::counting_semaphore 与 std::binary_semaphore,定义在 <semaphore> 中。
binary_semaphore[3] 只是 counting_semaphore 的一个特化别名:
using binary_semaphore = counting_semaphore<1>;好了,我们举一个简单的例子来使用一下:
// 全局二元信号量对象
// 设置对象初始计数为 0
std::binary_semaphore smph_signal_main_to_thread{ 0 };
std::binary_semaphore smph_signal_thread_to_main{ 0 };
void thread_proc() {
smph_signal_main_to_thread.acquire();
std::cout << "[线程] 获得信号" << std::endl;
std::this_thread::sleep_for(3s);
std::cout << "[线程] 发送信号\n";
smph_signal_thread_to_main.release();
}
int main() {
std::jthread thr_worker{ thread_proc };
std::cout << "[主] 发送信号\n";
smph_signal_main_to_thread.release();
smph_signal_thread_to_main.acquire();
std::cout << "[主] 获得信号\n";
}运行结果:
[主] 发送信号
[线程] 获得信号
[线程] 发送信号
[主] 获得信号acquire 函数就是我们先前说的“等待”(原子地减少计数),release 函数就是"释放"(原子地增加计数)。
信号量常用于发信/提醒而非互斥,通过初始化该信号量为 0 从而阻塞尝试 acquire() 的接收者,直至提醒者通过调用 release(n) “发信”。在此方面可把信号量当作条件变量的替代品,通常它有更好的性能。
假设我们有一个 Web 服务器,它只能处理有限数量的并发请求。为了防止服务器过载,我们可以使用信号量来限制并发请求的数量。
// 定义一个信号量,最大并发数为 3
std::counting_semaphore<3> semaphore{ 3 };
void handle_request(int request_id) {
// 请求到达,尝试获取信号量
std::cout << "进入 handle_request 尝试获取信号量\n";
semaphore.acquire();
std::cout << "成功获取信号量\n";
// 此处延时三秒可以方便测试,会看到先输出 3 个“成功获取信号量”,因为只有三个线程能成功调用 acquire,剩余的会被阻塞
std::this_thread::sleep_for(3s);
// 模拟处理时间
std::random_device rd;
std::mt19937 gen{ rd() };
std::uniform_int_distribution<> dis(1, 5);
int processing_time = dis(gen);
std::this_thread::sleep_for(std::chrono::seconds(processing_time));
std::cout << std::format("请求 {} 已被处理\n", request_id);
semaphore.release();
}
int main() {
// 模拟 10 个并发请求
std::vector<std::jthread> threads;
for (int i = 0; i < 10; ++i) {
threads.emplace_back(handle_request, i);
}
}运行测试。
这段代码很简单,以至于我们可以在这里来再说一条概念:
counting_semaphore是一个轻量同步原语,能控制对共享资源的访问。不同于 std::mutex,counting_semaphore允许同一资源进行多个并发的访问,至少允许LeastMaxValue个同时访问者[4]。binary_semaphore是std::counting_semaphore的特化的别名,其LeastMaxValue为 1。
LeastMaxValue 是我们设置的非类型模板参数,意思是信号量维护的计数最大值。我们这段代码设置的是 3,也就是允许 3 个同时访问者。
虽然说是说有 LeastMaxValue 可能不是最大,但是我们通常不用在意这个事情,MSVC STL 的实现中 max 函数就是直接返回
LeastMaxValue,将它视为信号量维护的计数最大值即可。
牢记信号量的基本的概念不变,计数的值不能小于 0,如果当前信号量的计数值为 0,那么执行“等待”(acquire)操作的线程将会一直阻塞。明白这点,那么就都不存在问题。
通过这种方式,可以有效控制 Web 服务器处理并发请求的数量,防止服务器过载。
C++20 闩与屏障
闩 (latch) 与屏障 (barrier) 是线程协调机制,允许任何数量的线程阻塞直至期待数量的线程到达。闩不能重复使用,而屏障则可以。
std::latch:单次使用的线程屏障std::barrier:可复用的线程屏障
它们定义在标头 <latch> 与 <barrier>。
与信号量类似,屏障也是一种古老而广泛应用的同步机制。许多系统 API 提供了对屏障机制的支持,例如 POSIX 和 Win32。此外,OpenMP 也提供了屏障机制来支持多线程编程。
std::latch
“闩” ,中文语境一般说“门闩” 是指门背后用来关门的棍子。不过不用在意,在 C++ 中的意思就是先前说的:单次使用的线程屏障。
latch 类维护着一个 std::ptrdiff_t 类型的计数[5],且只能减少计数,无法增加计数。在创建对象的时候初始化计数器的值。线程可以阻塞,直到 latch 对象的计数减少到零。由于无法增加计数,这使得 latch 成为一种单次使用的屏障。
std::latch work_start{ 3 };
void work(){
std::cout << "等待其它线程执行\n";
work_start.wait(); // 等待计数为 0
std::cout << "任务开始执行\n";
}
int main(){
std::jthread thread{ work };
std::this_thread::sleep_for(3s);
std::cout << "休眠结束\n";
work_start.count_down(); // 默认值是 1 减少计数 1
work_start.count_down(2); // 传递参数 2 减少计数 2
}运行结果:
等待其它线程执行
休眠结束
任务开始执行在这个例子中,通过调用 wait 函数阻塞子线程,直到主线程调用 count_down 函数原子地将计数减至 0,从而解除阻塞。这个例子清楚地展示了 latch 的使用,其逻辑比信号量更简单。
由于 latch 的计数不可增加,它的使用通常非常简单,可以用来划分任务执行的工作区间。例如:
std::latch latch{ 10 };
void f(int id) {
//todo.. 脑补任务
std::this_thread::sleep_for(1s);
std::cout << std::format("线程 {} 执行完任务,开始等待其它线程执行到此处\n", id);
latch.arrive_and_wait();
std::cout << std::format("线程 {} 彻底退出函数\n", id);
}
int main() {
std::vector<std::jthread> threads;
for (int i = 0; i < 10; ++i) {
threads.emplace_back(f,i);
}
}运行测试。
arrive_and_wait 函数等价于:count_down(n); wait();。也就是减少计数 + 等待。这意味着
必须等待所有线程执行到 latch.arrive_and_wait(); 将 latch 的计数减少至 0 才能继续往下执行。这个示例非常直观地展示了如何使用 latch 来划分任务执行的工作区间。
由于 latch 的功能受限,通常用于简单直接的需求,不少情况很多同步设施都能完成你的需求,在这个时候请考虑使用尽可能功能最少的那一个。
- 使用功能尽可能少的设施有助于开发者阅读代码理解含义。如果使用的是一个功能丰富的设施,可能就无法直接猜测其意图。
std::barrier
上节我们学习了 std::latch ,本节内容也不会对你构成难度。
template< class CompletionFunction = /* 未指定 */ >
class barrier;CompletionFunction - 函数对象类型。
std::barrier 和 std::latch 最大的不同是,前者可以在阶段完成之后将计数重置为构造时传递的值,而后者只能减少计数。我们用一个非常简单直观的示例为你展示:
std::barrier barrier{ 10,
[n = 1]()mutable noexcept {std::cout << "\t第" << n++ << "轮结束\n"; }
};
void f(int start, int end){
for (int i = start; i <= end; ++i) {
std::osyncstream{ std::cout } << i << ' ';
barrier.arrive_and_wait(); // 减少计数并等待 解除阻塞时就重置计数并调用函数对象
std::this_thread::sleep_for(300ms);
}
}
int main(){
std::vector<std::jthread> threads;
for (int i = 0; i < 10; ++i) {
threads.emplace_back(f, i * 10 + 1, (i + 1) * 10);
}
}可能的运行结果:
1 21 11 31 41 51 61 71 81 91 第1轮结束
12 2 22 32 42 52 62 72 92 82 第2轮结束
13 63 73 33 23 53 83 93 43 3 第3轮结束
14 44 24 34 94 74 64 4 84 54 第4轮结束
5 95 15 45 75 25 55 65 35 85 第5轮结束
6 46 16 26 56 96 86 66 76 36 第6轮结束
47 17 57 97 87 67 77 7 27 37 第7轮结束
38 8 28 78 68 88 98 58 18 48 第8轮结束
9 39 29 69 89 99 59 19 79 49 第9轮结束
30 40 70 10 90 50 60 20 80 100 第10轮结束注意输出的规律,第一轮每个数字最后一位都是 1,第二轮每个数字最后一位都是 2……以此类推,因为我们分配给每个线程的输出任务就是如此,然后利用了屏障一轮一轮地打印。
arrive_and_wait 等价于 wait(arrive());。原子地将期待计数减少 1,然后在当前阶段的同步点阻塞直至运行当前阶段的阶段完成步骤。
arrive_and_wait() 会在期待计数减少至 0 时调用我们构造 barrier 对象时传入的 lambda 表达式,并解除所有在阶段同步点上阻塞的线程。之后重置期待计数为构造中指定的值。屏障的一个阶段就完成了。
- 并发调用
barrier除了析构函数外的成员函数不会引起数据竞争。
另外你可能注意到我们使用了 std::osyncstream ,它是 C++20 引入的,此处是确保输出流在多线程环境中同步,避免除数据竞争,而且将不以任何方式穿插或截断。
虽然
std::cout的operator<<调用是线程安全的,不会被打断,但多个operator<<的调用在多线程环境中可能会交错,导致输出结果混乱,使用std::osyncstream就可以解决这个问题。开发者可以尝试去除std::osyncstream直接使用std::cout,效果会非常明显。
使用 arrive 或 arrive_and_wait 减少的都是当前屏障计数,我们称作“期待计数”。不管如何减少计数,当完成一个阶段,就重置期待计数为构造中指定的值了。
标准库还提供一个函数 arrive_and_drop 可以改变重置的计数值:它将所有后继阶段的初始期待计数减少一,当前阶段的期待计数也减少一。
不用感到难以理解,我们来解释一下这个概念:
std::barrier barrier{ 4 }; // 初始化计数为 4 完成阶段重置计数也是 4
barrier.arrive_and_wait(); // 当前计数减 1,不影响之后重置计数 4
barrier.arrive_and_drop(); // 当前计数与重置之后的计数均减 1 完成阶段会重置计数为 3arrive_and_drop 可以用来控制在需要的时候,让一些线程退出同步,如:
std::atomic_int active_threads{ 4 };
std::barrier barrier{ 4,
[n = 1]() mutable noexcept {
std::cout << "\t第" << n++ << "轮结束,活跃线程数: " << active_threads << '\n';
}
};
void f(int thread_id) {
for (int i = 1; i <= 5; ++i) {
std::osyncstream{ std::cout } << "线程 " << thread_id << " 输出: " << i << '\n';
if (i == 3 && thread_id == 2) { // 假设线程 ID 为 2 的线程在完成第三轮同步后退出
std::osyncstream{ std::cout } << "线程 " << thread_id << " 完成并退出\n";
--active_threads; // 减少活跃线程数
barrier.arrive_and_drop(); // 减少当前计数 1,并减少重置计数 1
return;
}
barrier.arrive_and_wait(); // 减少计数并等待,解除阻塞时重置计数并调用函数对象
}
}
int main() {
std::vector<std::jthread> threads;
for (int i = 1; i <= 4; ++i) {
threads.emplace_back(f, i);
}
}运行测试。
初始线程有 4 个,线程 2 在执行了三轮同步便直接退出了,调用 arrive_and_drop 函数,下一个阶段的计数会重置为 3,也就是执行完第三轮同步后只有三个活跃线程继续执行。查看输出结果,非常的直观。
这样,arrive_and_drop 的作用就非常明显了,使用也十分的简单。
最后请注意,我们的 lambda 表达式必须声明为 noexcept ,因为 std::barrier 要求其函数对象类型必须是不抛出异常的。即要求 std::is_nothrow_invocable_v<_Completion_function&> 为 true,见 MSVC STL。
std::barrier barrier{ 1,[] {} };按照标准规定,这行代码会产生一个编译错误。因为传入的函数对象它不是 noexcept 的。不过,在 gcc 与 clang(即 libstdc++ 和 libc++)均可以通过编译,这是因为它们没有进行相应的检测,存在缺陷,为了代码的可维护性开发者应遵守标准规定,确保传入的函数对象是 noexcept 的。
总结
在并发编程中,同步操作对于并发编程至关重要。如果没有同步,线程基本上就是独立的,因其任务之间的相关性,才可作为一个整体执行(比如第二章的并行求和)。本章讨论了多种用于同步操作的工具,包括条件变量、future、promise、package_task、信号量。同时,详细介绍了 C++ 时间库的知识,以使用并发支持库中的“限时等待”。还使用 CMake + Qt 构建了一个带有 UI 界面的示例,展示异步多线程的必要性。最后介绍了 C++20 引入的两种新的并发设施,信号量、闩与屏障。
在讨论了 C++ 中的高级工具之后,现在让我们来看看底层工具:C++ 内存模型与原子操作。
注:多个线程能在不同的 shared_ptr 对象上调用所有成员函数(包含复制构造函数与复制赋值)而不附加同步,即使这些实例是同一对象的副本且共享所有权也是如此。若多个执行线程访问同一 shared_ptr 对象而不同步,且任一线程使用 shared_ptr 的非 const 成员函数,则将出现数据竞争;
std::atomic<shared_ptr>能用于避免数据竞争。文档。 ↩︎注:如果信号量只有二进制的 0 或 1,称为二进制信号量(binary semaphore),这就是这个类型名字的由来。 ↩︎
注:如其名所示,LeastMaxValue 是最小 的最大值,而非实际 最大值。静态成员函数
max()可能产生大于 LeastMaxValue 的值。 ↩︎注:通常的实现是直接保有一个
std::atomic<std::ptrdiff_t>私有数据成员,以保证计数修改的原子性。原子类型在我们第五章的内容会详细展开。 ↩︎